Apple Pies and License Plate Recognitions from Scratch

The idea of creating something from scratch is both intimidating and exciting. It is tough to stare at a blank screen (usually a programming IDE), waiting for us to type the first characters of a big new project. But this is also a moment full of new possibilities, experiments, and learning. And as Carl Sagan once said, “if you wish to make an apple pie from scratch you must first invent the universe”. With that cosmic perspective in mind, let’s set our expectations straight on what we mean by “from scratch” and what we want to achieve:
- Any Deep Learning framework allowed: pytorch, JAX, keras, etc.
- Use the fewest libraries possible: this is both good for local debugging, general code understanding (i.e., our code does not jump into a black box), and makes it much more flexible, such as upgrading our frameworks to newer versions.
- Should run fast on CPU: the GPU world is great, but I want something that runs somewhat fast on CPU. I’ll say that 100ms on my low/midrange notebook is good enough (AMD Ryzen 7 5700U).
- Simple solution: ideally I would want a single end-to-end network, i.e., pass an image and receive the list of plates with their text, but this might be too challenging…
So with that in mind, what is a License Plate Recognition (aka LPR)? It’s just a system that both detects and reads the license plates from an image/video. It is commonly used in private parking lots, traffic monitoring systems, and similar applications.
Solution Pipeline
A good place to start is to examine the current state-of-the-art approaches, though license plate recognition isn’t currently a hot research topic. Drawing from my past experience (this won’t be my first nor second LPR implementation), I believe that a conceptually simple and easy to implement solution would be to tackle this problem in 2 stages:
- Plate Detection: given an image or video frame, find all the license plates positions. Usually as rectangular bounding boxes, but the plate corners would be better.
- Plate Recognition: for each detection, crop the plate image and run an OCR network.
This is not an end-to-end solution as I wanted, but it’s so much easier to compose and train that it seems like a good approach. This gives us two areas to research: detection and OCR.
Choosing our Networks
For detection, I had great results with SCRFD. It is a network specially tailored for face detection, and the reason why a regular Object Detector was not good enough for faces was quite interesting: most faces are small compared to the whole image. Therefore, regular CNN approaches struggle with this because their deeper layers, which are responsible for generating complex features, lose spatial resolution due to successive downsampling operations like MaxPool.
How this is solved: with a powerful neck that combines the information of several higher dimensional layers with the later and smaller ones. This allows the network to get sophisticated features even for small objects on the image. This approach combined with a carefully crafted backbone made SCRFD a really small and fast face detection network.
But why am I talking so much about faces? Well, in many scenarios, I believe that license plates also have the same problem: they appear very small within the whole image. Therefore, I believe that this approach should also work, and we are going to stick to it.
And for OCR? I’ve read many papers on what they usually call Text Recognition or Scene Text Recognition. I’ve found that many state-of-the-art papers are combining some language model to add a prior on the pure OCR. This was previously done using a dictionary and beam search, where we would get a word like “NUMBR” and it would be changed to “NUMBER”. Using a Language Model is, however, a more robust solution.
It is important, though, to check our scenario: license plates are almost random, usually only containing some simple structure such as number of characters and fixed places for numbers and letters. Using a language model just seems overkill for such simple rules, and possibly will even hurt the performance if we are not careful during the training stage.
After some more searching, I’ve found MaskOCR. It uses Vision Transformer (ViT) for encoding our words, which is, in itself, a much more intuitive approach than CNN-based methods for this particular task. The transformer can naturally subdivide our image into vertical patches, and their relationships will be given by the attention phase. I will not get into many details on how it works, but it first has an initial training process that uses masked autoencoders (MAE) to initialize the encoder part. Afterwards, we attach a decoder with a linear layer and do the final OCR predictions. It is a simple enough solution that we can implement, and it achieved really good results, so that’s our OCR network.
Implementing Them
Fortunately, SCRFD already has an open-source implementation available, which provided a great starting point. However, it uses the OpenMMLab libraries. They are awesome, and we can easily change some configs and get some really new and state-of-the-art networks. But with this great flexibility comes a serious drawback: the installation process is janky. We have to use openmim instead of pip or conda, making it harder to config our environment. Also, it is quite strict with CUDA and PyTorch versions, so we are kinda stuck with older releases.
This was a big no-go for this project, so I decided to directly get the code that I need and drop this requirement altogether. It took a bit of work, changing some interfaces and simplifying some details, but I’ve managed to do it. And in the process, I’ve learned a lot about how OpenMMDetection works, which is a great thing.
Also, I decided to use the EfficientDet BiFPN (bi-directional feature pyramid network) for the neck. It proved itself as a very strong neck, and I think that being bi-directional is a really good strategy to make the best use of our limited backbone features. And I’m calling them limited only because I’ll use the smallest backbone that I can find, and that was MobileNetV4. In the end it is a little bit different from SCRFD, but the main gist of it remains, only updating some parts.
For MaskOCR it was a bit trickier: there was no implementation available. This is not that big of a deal, though, since I was able to get the more complicated stuff from ViT Pytorch, and only had to piece everything together and set up the training process. It took a bit of work but it paid off.
Both implementations can be found here: https://github.com/gfickel/alpr
Training Everything
Training an LPR system requires both quality data and careful parameter tuning. Let’s break down the process, starting with dataset selection and preparation.
The first step on the training process is actually finding and preparing our data. I’ve found a really interesting dataset called CCPD2019. It contains over 300K annotated images of Chinese license plates, and even has some subsets with different scenarios. Those are the ones that I’m using:
- ccpd_base: good set of images, used for training
- ccpd_weather: images captured in heavy weather, used for validation
- ccpd_challenge: used for testing
The training process was somewhat straightforward: I’ve used AdamW, dlib plateau detection to check when the learning rate should be decreased, and for the detection model, I’ve set the backbone learning rate to 1/10 of the rest of the network. All of this and the final weights can be found on my GitHub repo: https://github.com/gfickel/alpr
Hyperparameters Tested
For the Detection network, I only changed the start learning rate and used weight_decay=0.01 with the largest batch size that my GPU could handle. I did a quick check on some possible backbones such as ResNet and EfficientNet but mainly stuck with MobileNet V4 since it was providing the bigger bang for the buck.
Training MaskOCR was a little bit more complicated. Here are some key parameters:
- image size: I started using 32x128, but when I changed to 48x192 I quickly noticed a bump in accuracy.
- num encoder layers: I tried several combinations, but every time I used less than 8 the accuracy quickly dropped, and higher numbers stayed the same or increased overfitting. I ended up using 8.
- num decoder layers: also tested several values, and 6 was the best one.
- dropout: I added dropout both on encoder and decoder phases with a value of 0.25, all in the name of avoiding overfitting.
- num encoder heads: either 8 or 12 were giving me good results but 12 was just a tad bit better.
- embed_dim: great influence on the results. 624 was the sweet spot for me.
This network also had a tendency to overfit. I had to write my custom augmentation code and added a parameter to control its strength. Even with 300K images, heavy augmentations were fundamental in getting good results.
Results
We achieved 93% accuracy on ccpd_challenge, the hardest set and usually reserved for testing. Notice that there are some annotation problems, mostly invalid plates and humanly unreadable plates. We can argue that “unreadable” is somewhat subjective, and that the model should be able to outperform humans. However, this makes it quite challenging to determine if the mistake came from the network or the annotation. Here is a very well-behaved example:
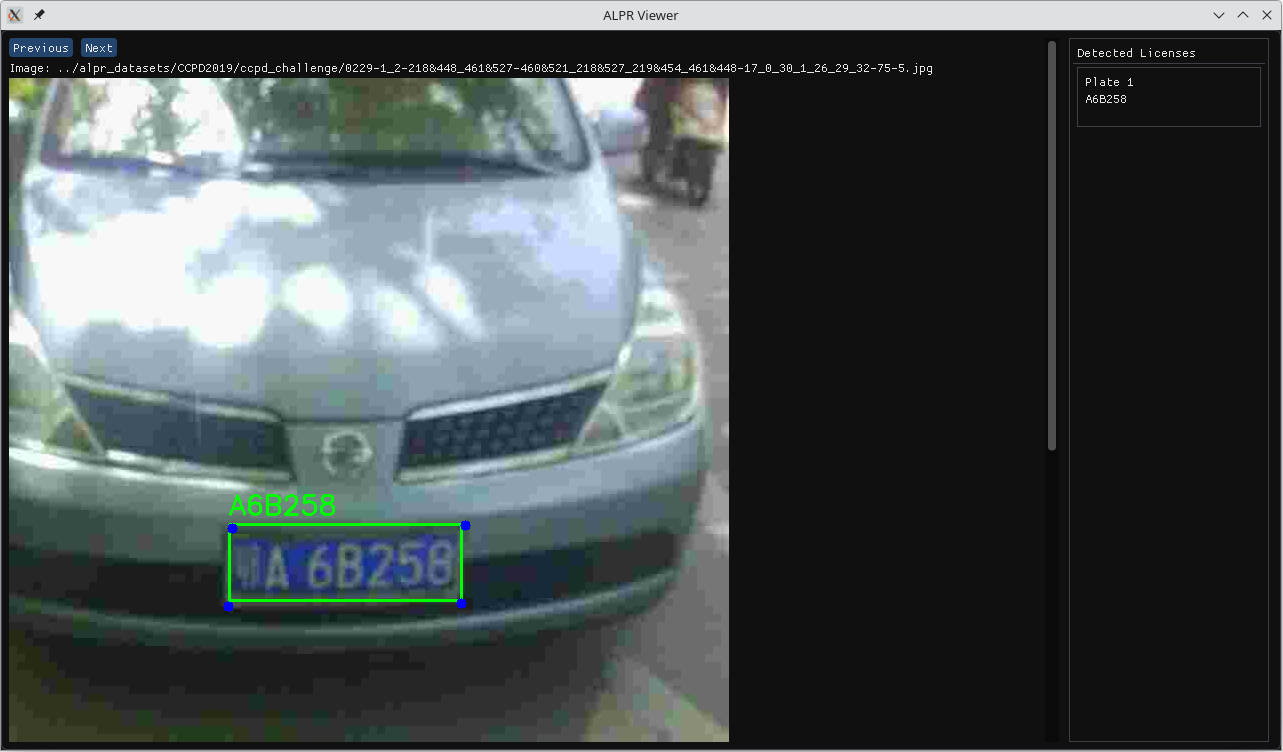
And what about the runtime? I’ve run some tests on my personal notebook, with an AMD Ryzen 7 5700U (with a modest TDP of 15W), 12GB RAM, Ubuntu 23.04:
- Detection: ~80ms
- OCR (per plate): ~48ms
We’ve exceeded our initial budget of 100ms by 28ms, which is significant. We definitely can iterate further on both networks, testing the impact of some hyperparameters on the final runtime/accuracy and find some better ones. However, I’m running low on time, and I’m happy with where we are.
Missing Steps for Deploy
There is a world of difference between ideal research conditions and actually deploying a Machine Learning model. It is important to define this at the very start of the project and update our priorities and goals accordingly. Here are some questions that we should always ask:
- Is it going to work on pictures or video?
- Maximum latency? 100ms, 1s, 10s?
- Will it run on Cloud? If so, on CPU, GPU, TPU?
- Will it run on smartphones? Android, iOS? Minimum SDK and phone specs?
- What metrics should we use? FAR/FRR, AuC? And what is our goal, remembering that there is no perfect system.
These questions will give us a set of constraints that we must follow: maximum latency and where should we measure it (CPU, GPU, smartphone), model size (really important for smartphones), architecture design (perhaps we can use some Android/iOS AI building blocks), etc.
Some Tips
It is a very fun and challenging process to try and make something as big as an LPR, but there are many pitfalls down the bumpy road. Here are some key tips for a much faster and productive process:
- Good Logging: use a platform that makes it easy to compare multiple training sessions. I’m using Weights and Bias but you should use whatever you like.
- FAST Iteration: quick iteration time doesn’t mean only making a code change and running/debugging, but also fast trains. Ideally a full trained model should take no longer than an hour. Usually you should use a smaller train dataset and some smarter way to train, such as fit_one_cycle and lr_find. This way you can quickly test several ideas before sticking to a few and doing a full, lengthy train.
- Good Debug Experience: either through notebooks or through an IDE, my preferred way. Programming is hard, and tracking all the tensors shapes and their modifications is usually quite tricky, so having an easy way to debug your code along the way can make your life so much easier.
- LLMs Are Quite Good: I’m slightly embarrassed to admit that I’m a late LLM adopter, but I’m finding they are really helpful. However, they make a lot of mistakes, so you should never blindly trust them, but they are awesome in several areas such as writing boilerplate code, serving as an interactive documentation for many popular libs, and explaining some concepts with code and plots.
And if my first image left you wanting an apple pie, look no further than the cooking master J. Kenji López-Alt help here.